
DeepSeek-OCRとは何か
DeepSeek-OCR完全ガイド:テキストを画像で圧縮する革新的AI技術の全貌
はじめに
2025年10月、中国のAI企業DeepSeekが発表した「DeepSeek-OCR」は、AI業界に衝撃を与えました。その名称から単なる高性能なOCRツールと思われがちですが、実際には大規模言語モデル(LLM)が抱える根本的な課題に挑む、革新的なアプローチを提示しています。
本記事では、DeepSeek-OCRの技術的な仕組みから実用的な活用法まで、徹底的に解説していきます。
DeepSeek-OCRとは何か
DeepSeek-OCRは、光学文字認識(Optical Character Recognition)の技術を応用した、文脈の光学的圧縮(Contexts Optical Compression)を実現するAIシステムです。しかし、従来のOCRとは本質的に異なる目的を持っています。
従来のOCRが「画像からテキストを抽出する」ことを目的としているのに対し、DeepSeek-OCRは「テキストを画像として圧縮し、効率的に処理する」という逆転の発想に基づいています。
核心となるアイデア
「一枚の画像は千の言葉に値する」という格言を、文字通り技術的に実現したのがDeepSeek-OCRです。長大なテキストを画像として表現することで、LLMが処理するトークン数を劇的に削減します。
主な特徴: - 10倍圧縮で97%の精度を達成 - 20倍圧縮でも約60%の精度を維持 - 従来のビジョン言語モデルと比較してトークン数を85%削減 - 単一のNVIDIA A100 GPUで1日20万ページ以上の処理が可能
なぜ今、DeepSeek-OCRが注目されているのか
LLMの抱える課題
大規模言語モデルには、避けて通れない根本的な問題があります。それは、処理するテキストが長くなればなるほど、計算コストが指数関数的に増大するというものです。
例えば、100ページの契約書をLLMに読み込ませようとすると: - テキストトークン数:数万〜数十万トークン - メモリ消費量:膨大 - 処理コスト:非常に高額 - レイテンシー:大幅な遅延
DeepSeek-OCRによる解決策
DeepSeek-OCRは、この問題に対して「テキストで処理するから効率が悪い。画像として圧縮すれば良いのでは?」という発想で挑みました。
具体例: - 1000語のテキスト → 従来は約1000トークン必要 - 同じ内容を画像化 → わずか100の視覚トークンで表現可能 - 結果:10分の1のトークンで同等の情報を保持
この圧縮により、LLMが扱えるコンテキストの範囲が飛躍的に拡大し、理論上は無制限のコンテキスト処理への道が開かれます。
光学的圧縮の仕組み
3つのステップで理解する圧縮プロセス
DeepSeek-OCRの圧縮処理は、以下の3つのステップで構成されています。
ステップ1:テキストの画像化 処理したいテキスト全体を、一枚の画像としてレンダリングします。これにより、テキストが2次元の視覚情報に変換されます。
ステップ2:DeepEncoderによる圧縮 高性能な画像エンコーダー「DeepEncoder」が、画像を読み込み、非常にコンパクトな「ビジョントークン」に圧縮します。数千のテキストトークンが、数百のビジョントークンに変換されます。
ステップ3:LLMでの処理と復元 圧縮されたビジョントークンがLLMに入力され、処理されます。最後に、「DeepSeek3B-MoE」デコーダーが、ビジョントークンを元の正確なテキスト情報に復元します。
なぜ画像の方が効率的なのか
画像は本質的に情報を圧縮した形式です。人間の視覚システムも同様の方法で情報を処理しています。
- 空間的な配置:テキストの位置関係が保持される
- 2次元構造:レイアウト情報も含めて表現できる
- 高い情報密度:少ないデータ量で多くの情報を保持
DeepSeek-OCRのアーキテクチャ
システム構成
DeepSeek-OCRは、2つの主要コンポーネントで構成されています。
1. DeepEncoder(ビジョンエンコーダー)
パラメータ数:約3億8000万
DeepEncoderは、3つのサブコンポーネントから構成される高度なビジョンエンコーダーです。
構成要素:
- SAM-base(80Mパラメータ)
- Window Attentionによる局所的な視覚処理
- 画像を小さなウィンドウに分割して処理
-
高解像度入力でも低い活性化コストを維持
-
16倍圧縮器
- 畳み込み層を使用したトークン圧縮
- 画像パッチから重要な特徴のみを抽出
-
トークン数を16分の1に削減
-
CLIP-large(300Mパラメータ)
- Global Attentionで全体の文脈を把握
- 画像とテキストをリンクさせる
- グローバルな視覚知識の集約
処理フロー: 1024×1024ピクセルの画像 → 4096トークン(生の状態)→ DeepEncoderで処理 → 256トークンに圧縮
2. DeepSeek3B-MoE-A570M(デコーダー)
総パラメータ数:30億 アクティブパラメータ:約5億7000万
Mixture-of-Experts(MoE)アーキテクチャを採用したデコーダーです。
特徴: - 64個の専門家(エキスパート)を保有 - 各ステップで6個のエキスパートを動的に選択 - 軽量ながら効率的なテキスト再構成を実現
MoE構造により、処理内容に応じて最適な専門家を選択することで、高い精度と効率性を両立しています。
データフローの全体像
入力画像(文書)
↓
DeepEncoder(圧縮)
├─ SAM-base(局所処理)
├─ 16倍圧縮器(トークン削減)
└─ CLIP-large(全体文脈)
↓
ビジョントークン(64〜400個)
↓
DeepSeek3B-MoE(復元)
└─ 64個のエキスパートから最適な6個を選択
↓
出力テキスト(Markdown形式など)
驚異的な性能指標
圧縮率と精度のバランス
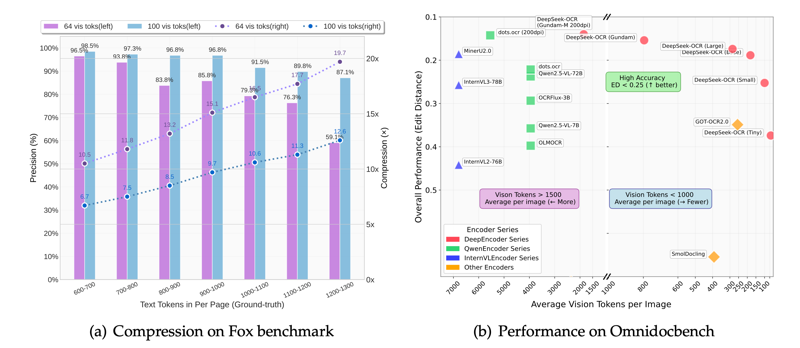
DeepSeek-OCRの性能を示す最も重要な指標が、圧縮率と精度の関係です。
Foxベンチマークの結果:
| ページ語数 | 視覚トークン | 圧縮率 | 精度 |
|---|---|---|---|
| 600-700語 | 100個 | 6.7倍 | 98.5% |
| 900-1000語 | 100個 | 10倍 | 96.8% |
| 1200-1300語 | 64個 | 20倍 | 59.1% |
分析: - 10倍圧縮までは、ほぼロスレス(97%以上の精度) - 20倍圧縮でも過半数の情報を保持 - 用途に応じて圧縮率を調整可能
他モデルとの比較
OmniDocBenchベンチマーク:
| モデル | トークン数/ページ | 相対性能 |
|---|---|---|
| GOT-OCR 2.0 | 256 | ベースライン |
| DeepSeek-OCR(Small) | 100 | GOT-OCR 2.0を上回る |
| MinerU 2.0 | 6000+ | ベースライン |
| DeepSeek-OCR(Large) | 800未満 | MinerU 2.0を上回る |
DeepSeek-OCRは、より少ないトークンで既存の高性能モデルを凌駕しています。
処理速度
本番環境での性能: - 単一A100-40G GPU:1日20万ページ以上 - 20ノード(各8台のA100):1日3300万ページ - 処理時間:数秒〜数十秒/ページ(解像度モードにより変動)
この高速処理能力により、大規模なデータセット生成やリアルタイム処理が可能になります。
解像度モードの使い分け
DeepSeek-OCRは、用途に応じて5つの解像度モードを提供しています。これは他のOCRシステムにはない独自の機能です。
ネイティブモード(固定解像度)
1. Tinyモード - 解像度:512×512ピクセル - トークン数:64個 - 用途:シンプルな文書、リソース制約環境 - 特徴:最小トークンで高速処理
2. Smallモード - 解像度:640×640ピクセル - トークン数:100個 - 用途:一般的な文書(推奨デフォルト) - 特徴:速度と精度のバランスが最良
3. Baseモード - 解像度:1024×1024ピクセル - トークン数:256個 - 用途:詳細な文書、複雑なレイアウト - 特徴:高精度な細部認識
4. Largeモード - 解像度:1280×1280ピクセル - トークン数:400個 - 用途:技術文書、学術論文 - 特徴:最高レベルの精度
動的モード
5. Gundamモード - 解像度:可変(タイリング方式) - トークン数:n×100 + 256(nはタイル数、2〜9) - 用途:特大の文書、複雑な図表を含む文書 - 特徴:複数の640×640タイル + 1024×1024グローバルビュー
動作原理: Gundamモードは、画像を複数のタイルに分割し、各タイルを局所的に処理した後、全体像を1枚のグローバルビューで捉えます。
文書種別ごとの推奨モード
| 文書タイプ | 推奨モード | 編集距離(精度指標) |
|---|---|---|
| 書籍 | Small | 0.078 |
| 新聞 | Small | 0.068 |
| 学術論文 | Large | 0.052 |
| 技術報告書 | Large/Gundam | 0.045 |
| 財務諸表 | Gundam | 0.072 |
*編集距離が小さいほど高精度
選択のガイドライン: - シンプルな文書 → Smallモードから開始 - 精度が不足 → より高解像度のモードへ - 小さいフォントや高密度テキスト → Gundamモード
実用的な活用事例
1. 長文ドキュメント解析
課題: 100ページ以上の契約書や法律文書をLLMで分析したい
解決策: DeepSeek-OCRで圧縮してからGPT-4などに入力 - トークン数:従来の10分の1 - コスト削減:約90% - 処理速度:大幅に向上
具体的な用途: - 法務文書の条文抽出 - 契約書のリスク分析 - コンプライアンスチェック
2. 企業内文書の自動化処理
ユースケース: - 社内レポートの自動要約 - FAQ自動生成システム - 文書検索・分類システム
導入メリット: - コールセンターの応答精度向上 - ナレッジベースの自動構築 - 業務効率の大幅改善
3. AI研究のためのデータ生成
活用方法: DeepSeek-OCR自身の高速性を活かした大規模データ生成
実績: - 1日20万ページ以上のOCRデータ生成 - 他のAIモデルのトレーニングデータ作成 - 多言語データセットの構築
4. 金融・科学・医療分野での応用
適用領域: - 財務諸表の自動分析 - 科学論文の体系的レビュー - 医療記録のデジタル化と解析
強み: - 数値データの高精度認識 - グラフ・図表の理解 - 複雑なレイアウトへの対応
5. 多言語文書処理
対応言語: 英語、中国語を中心に100以上の言語に対応
特徴: - 手書き文字への対応(今後さらに改善予定) - 歪んだ画像の処理 - 多言語混在文書の認識
導入方法とリソース
オープンソースとライセンス
DeepSeek-OCRはMITライセンスで公開されており、商用利用を含めて自由に使用できます。
公開リソース: - GitHubリポジトリ:https://github.com/deepseek-ai/DeepSeek-OCR - Hugging Face:https://huggingface.co/deepseek-ai/DeepSeek-OCR - arXiv論文:arXiv:2510.18234
技術要件
推奨環境: - GPU:NVIDIA A100(40GB以上推奨)、またはRTX 3060(12GB)以上 - CUDA:11.8以上 - PyTorch:2.6.0 - Transformers:4.46.3以上 - Flash Attention:2.7.3
メモリ要件: - 最小:約7GB(モデルサイズ6.6GB) - 推奨:12GB以上(バッチ処理を含む)
基本的な実装例
vLLMを使用した実装:
from vllm import LLM, SamplingParams
from PIL import Image
# モデルのインスタンス化
llm = LLM(
model="deepseek-ai/DeepSeek-OCR",
enable_prefix_caching=False,
mm_processor_cache_gb=0
)
# 画像の読み込み
image = Image.open("document.png").convert("RGB")
# 推論の実行
prompt = "<image>\nFree OCR."
model_input = {
"prompt": prompt,
"multi_modal_data": {"image": image}
}
sampling_param = SamplingParams(
temperature=0.0,
max_tokens=8192
)
# OCR実行
output = llm.generate([model_input], sampling_param)
print(output[0].outputs[0].text)
Transformersを使用した実装:
from transformers import AutoModel, AutoTokenizer
import torch
# モデルとトークナイザーの読み込み
model_name = 'deepseek-ai/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(
model_name,
trust_remote_code=True
)
model = AutoModel.from_pretrained(
model_name,
trust_remote_code=True,
use_safetensors=True
)
model = model.eval().cuda().to(torch.bfloat16)
# 画像の処理とOCR実行
# (詳細は公式ドキュメントを参照)
セットアップ手順
- リポジトリのクローン
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
cd DeepSeek-OCR
- 依存関係のインストール
pip install torch==2.6.0 torchvision==0.21.0
pip install vllm
pip install -r requirements.txt
pip install flash-attn==2.7.3 --no-build-isolation
- モデルの実行
python run_dpsk_ocr_image.py
トラブルシューティング
よくある問題:
- GPU メモリ不足
- 解決策:より小さい解像度モード(TinyまたはSmall)を使用
-
バッチサイズを削減
-
依存関係のエラー
- 確認:CUDA、PyTorch、Transformersのバージョン互換性
-
推奨:公式ドキュメントの環境設定に従う
-
PDF入力の非対応
- 対策:PDFを画像(PNG/JPEG)に変換してから処理
- ツール:pdf2imageなどを使用
従来のOCRとの違い
技術的な進化ポイント
1. 処理パラダイムの転換
従来のOCR: - 画像 → テキスト抽出 → 1次元データ - 目的:文字認識の精度向上
DeepSeek-OCR: - テキスト → 画像化 → 圧縮 → 2次元データ保持 - 目的:効率的なコンテキスト圧縮
2. ディープラーニングの活用度
TesseractなどのレガシーOCR: - ルールベースのパターンマッチング - 手書き文字や歪みに弱い - 多言語対応が限定的
AI-OCR(従来型): - 深層学習による認識精度向上 - kNN法、SVM法、CNNなどの機械学習 - 手書き文字にも対応
DeepSeek-OCR: - Vision-Language Modelによる統合処理 - MoEアーキテクチャによる効率化 - コンテキストを保持した圧縮
3. レイアウト理解能力
従来のOCR: - 文字の羅列として処理 - レイアウト情報の喪失 - 表や図表の理解が困難
DeepSeek-OCR: - 2次元構造を保持 - 表、数式、図表を含めて理解 - 複雑なレイアウトにも対応
性能比較表
| 項目 | レガシーOCR | AI-OCR | DeepSeek-OCR |
|---|---|---|---|
| 手書き文字精度 | 10-70% | 90-95% | 90-95%+ |
| 印刷文字精度 | 80-90% | 97-98% | 97%(圧縮後) |
| トークン効率 | N/A | 標準 | 85%削減 |
| レイアウト理解 | × | △ | ◎ |
| 処理速度 | 高速 | 中速 | 超高速 |
| 多言語対応 | 限定的 | 良好 | 優秀(100+言語) |
| コスト | 低 | 中 | 低(圧縮効果) |
学習データとトレーニング
データセットの構成
DeepSeek-OCRは、多様なデータで訓練されています。
OCR 1.0データ(70%): - 3000万ページの多様なPDF - 100以上の言語 - 200万ページの高品質アノテーション(中国語・英語)
OCR 2.0データ(合成データ): - 1000万枚のチャート・グラフ - 500万の化学式 - 100万の幾何図形
一般的なビジョンデータ(20%): - LAIONデータセット - Wukongデータセット - キャプション、検出、グラウンディングタスク
テキストのみのデータ(10%): - 高品質な言語能力を保持するため
2段階トレーニング手法
ステージ1:DeepEncoderの事前学習 - Next-token predictionでエンコーダーを独立して訓練 - OCRデータと一般ビジョンデータを使用
ステージ2:統合トレーニング - エンコーダーとデコーダーを結合して訓練 - パイプライン並列化(4分割) - マルチモーダルデータとテキストデータの混合
訓練環境: - 20ノード × 8台のA100-40G GPU - 最適化手法:AdamW - 訓練速度: - テキストのみ:1日900億トークン - マルチモーダル:1日700億トークン
今後の展望と課題
技術的な可能性
1. 無制限コンテキストへの道
DeepSeek-OCRの圧縮技術は、理論上無制限のコンテキスト処理への道を開く可能性があります。直近のコンテキストを高解像度で保持しながら、古いコンテキストを圧縮することで、情報保持と効率性のバランスを実現できます。
応用例: - 書籍全体を一度に処理 - 長期的な会話履歴の保持 - 大規模文書コーパスの統合分析
2. LLMのメモリメカニズムの変革
DeepSeek-OCRは、長文コンテキストの歴史的圧縮やLLMにおける記憶忘却メカニズムの研究にも有望性を示しています。
研究方向: - 選択的記憶の実装 - 長期記憶と短期記憶の統合 - 効率的な知識蒸留
3. マルチモーダルAIの進化
DeepSeek-OCRの成功は、視覚情報とテキスト情報の統合処理における新たな標準となる可能性があります。
現在の課題
1. 手書き文字の認識精度
綺麗なデジタルドキュメントの読み取りは高精度ですが、手書きや歪んだスキャン画像については、まだ改善の余地があります。
改善策: - TrOCRなどの専門的な手書き認識モデルとの統合 - より多様な手書きデータでの追加訓練
2. 特殊なフォーマットへの対応
現時点では、一部の複雑な文書フォーマットへの対応が限定的です。
対応が必要な分野: - 古文書や歴史的資料 - 非標準的なレイアウト - 高度に装飾されたデザイン文書
3. リアルタイム処理の最適化
現在の処理速度は十分に高速ですが、エッジデバイスでのリアルタイム処理にはさらなる最適化が必要です。
取り組み: - モデルの軽量化 - 量子化技術の適用 - 専用ハードウェアの活用
コミュニティと今後の発展
オープンソースのメリット: - 研究コミュニティでの迅速な改善 - 多様なユースケースでの検証 - 商用製品への統合が容易
期待される発展: - 他のLLMとの統合ツールの開発 - ドメイン特化型モデルの派生 - クラウドサービスとしての提供
まとめ
DeepSeek-OCRは、単なるOCR技術の進化ではなく、AIの情報処理パラダイムそのものを変革する可能性を秘めた革新的な技術です。
重要なポイントの再確認
技術的優位性: 1. 10倍圧縮で97%の精度という驚異的な性能 2. トークン数85%削減による大幅なコスト削減 3. 1日20万ページという高速処理能力
実用的な価値: 1. 長文ドキュメント処理の効率化 2. 企業の文書管理システムへの応用 3. AI研究のためのデータ生成ツール
今後の展望: 1. 無制限コンテキスト処理への道筋 2. LLMのメモリメカニズムの革新 3. マルチモーダルAIの新しい標準
導入を検討すべき組織
推奨される用途: - 大量の文書を扱う法務・金融部門 - 研究機関やアカデミア - AI開発を行う企業 - ドキュメント管理システムの構築を検討中の組織
最後に
DeepSeek-OCRの登場は、「百聞は一見にしかず」という古い格言が、AI時代において新たな意味を持つことを示しています。テキストと画像の境界を曖昧にし、より効率的な情報処理を実現するこの技術は、今後のAI発展において重要な役割を果たすでしょう。
MITライセンスで公開されているため、誰でも自由に試すことができます。ぜひ、実際に手を動かして、この革新的な技術の可能性を体験してみてください。
参考リソース: - 公式GitHub:https://github.com/deepseek-ai/DeepSeek-OCR - Hugging Face:https://huggingface.co/deepseek-ai/DeepSeek-OCR - 技術論文:arXiv:2510.18234
最終更新:2025年11月