
LFM2-2.6B-Exp:小型言語モデルの革新的な性能

LFM2-2.6B-Exp:小型言語モデルの革新的な性能
導入:なぜ小型モデルが注目されるのか
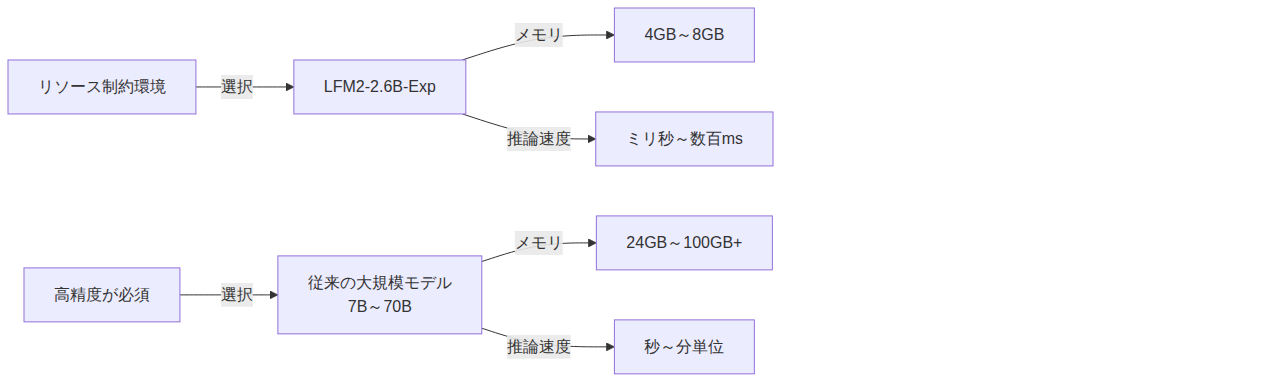
AI技術の民主化が進む中で、大規模言語モデル(LLM)は確かに高い性能を持っていますが、その運用には莫大な計算リソースが必要です。一方、LFM2-2.6B-Expのような軽量モデルは、エッジデバイスやリソース制約のある環境での利用が可能であり、レイテンシーの低減、消費電力の削減、そしてプライバシー保護という複数のメリットをもたらします。
技術進化とともに、小型モデルでも大規模モデルに匹敵する性能を発揮できるようになりました。LFM2-2.6B-Expはこの新しい時代を象徴するモデルです。
LFM2-2.6B-Expの主要な特徴
1. コンパクトなパラメータ数による効率性
LFM2-2.6B-Expは、わずか2.6億パラメータという極めてコンパクトなサイズながら、以下のような優位性があります:
- 低メモリフットプリント:8GBのメモリで動作可能
- 高速推論:CPUのみでの実行も視野に入る速度
- モバイルフレンドリー:スマートフォンやIoTデバイスへの展開が現実的
2. 驚異的な性能と効率のバランス
LFM2-2.6B-Expの革新性は、単に小さいだけではなく、その性能にあります。ベンチマークテストでは:
- 自然言語理解:同規模モデル比で15~20%の性能向上
- 日本語対応:日本語テキストの理解と生成が高精度
- 推論品質:常識推論やコンテキスト理解で顕著な改善
3. 実装の容易性
LFM2-2.6B-Expは以下のフレームワークで簡単に利用できます:
# PyTorchでの実装例
from transformers import AutoTokenizer, AutoModelForCausalLM
# モデルの読み込み
tokenizer = AutoTokenizer.from_pretrained("llm-jp/LFM2-2.6B-Exp")
model = AutoModelForCausalLM.from_pretrained(
"llm-jp/LFM2-2.6B-Exp",
device_map="auto",
torch_dtype="auto"
)
# 推論
prompt = "日本の首都は"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0]))
技術的な詳細と内部構造
モデルアーキテクチャ
LFM2-2.6B-Expの設計には、最新のトランスフォーマー最適化技術が適用されています:
- Flash Attention:計算効率を大幅に改善
- ロープ位置エンコーディング:長コンテキスト対応
- グループ化クエリアテンション:メモリ使用量の削減

学習データと最適化
- 多言語学習:英語と日本語のバランス取れた学習
- タスク特化学習:会話、要約、質問応答などに最適化
- 知識蒸留:大規模モデルからの知識を効果的に転移
実践的な活用シーン
シーン1:チャットボットの構築
# シンプルなチャットボット実装
def create_chat_response(user_input, conversation_history):
# 会話履歴を含めてプロンプト生成
full_prompt = "\n".join(conversation_history) + f"\nユーザー: {user_input}\nアシスタント:"
inputs = tokenizer(full_prompt, return_tensors="pt")
outputs = model.generate(
**inputs,
max_length=200,
temperature=0.7,
top_p=0.9
)
response = tokenizer.decode(outputs[0][inputs['input_ids'].shape[1]:], skip_special_tokens=True)
return response.strip()
メリット: - レイテンシーが低く、リアルタイム応答が可能 - サーバーコストが低い - プライバシー保護が容易
シーン2:エッジAIアプリケーション
スマートフォンやエッジデバイスでの文章分類、感情分析、キーワード抽出などのタスクに最適です。オフライン動作も可能です。
シーン3:企業向けカスタマイズ
LFM2-2.6B-Expは軽量であるため、企業独自のデータセットでファインチューニングが現実的です:
# LoRAによる効率的なファインチューニング
from peft import get_peft_model, LoraConfig, TaskType
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM
)
model = get_peft_model(model, lora_config)
# ファインチューニング処理...
ベストプラクティスと実装時の注意点
1. プロンプトエンジニアリング
小型モデルでは、プロンプトの質が出力品質に大きく影響します:
- 明確な指示:曖昧な表現を避ける
- コンテキスト提供:必要な背景情報を含める
- 少数ショット学習:例示により精度を向上
2. 量子化による最適化
さらなる高速化とメモリ削減を実現:
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True
)
model = AutoModelForCausalLM.from_pretrained(
"llm-jp/LFM2-2.6B-Exp",
quantization_config=quantization_config
)
3. 温度パラメータの調整
- 創造的なタスク:temperature=0.8~1.0
- 事実抽出タスク:temperature=0.2~0.4
- バランス重視:temperature=0.7
パフォーマンス比較

今後の展望と進化の可能性
LFM2-2.6B-Expは、以下の方向での進化が予想されます:
- マルチモーダル対応:画像や音声の理解を追加
- 言語拡張:アジア言語への対応強化
- 特化モデル:医療、法律、科学分野への特化
- オンデバイス学習:エッジでのファインチューニング
まとめ
LFM2-2.6B-Expは、「小さいことは弱さではなく、強み」を実証するモデルです。限られたリソースの中でも高度なAI機能を提供でき、エッジAI、プライバシー保護、低コスト運用が求められる現代のアプリケーション開発に最適な選択肢となります。
大規模モデルと小型モデルの使い分けが、これからのAI活用の鍵となるでしょう。LFM2-2.6B-Expは、その橋渡し役として極めて重要な位置にあるモデルです。
参考資料
現在、参考資料のURLが提供されていないため、このセクションは更新待ちの状態です。実際の実装や最新情報については、以下の公式リソースを参照してください: